

Why?

Why multiprocessing? Why testing while multiprocessing? For reliability mainly. That is, we separate the processes that are critical and we want the failures to be contained. And we want to test critical code! As thoroughly as possible. Having different processes imply that we must test that they interact and sync as expected.
My concrete use case. The heat control of my Home Automation is separate from sensor readings. And separate from web communication. If the internet goes down or some web service that I use misbehaves, the web process can capsize, the process where the heating control runs, will not miss a beat! Excellent!
Ofc, there is no free lunch so this isolation comes with a price when developing. Because this heterogeneous architecture, must be put to some integration tests, regardless of how well the code is tested in isolation. This is the focus here. How to test while heavily multiprocessing?
Oh, before moving forward, this is Python!
The code lives in my Git repo and here I show only relevant snippets.
Tools we will be using
PyTest – By far, my favorite testing framework! Is it available for C? C++? Other languages?
mocker – more precise pytest-mock integration. Not much difference from the (now) standard unittest.mock but the pytest supply the mocker as a fixture. No worries about contexts and returning the state back.
multiprocessing – Yes, the main actor. We will spawn processes and communicate with them.
logging – the standard Python library. We will configure one or two loggers.
coverage – more precise, pytest-cov library. Again, a wrapper over coverage.py.

What can I find here?
- A small primer on multiprocessing
- How to log from different processes
- Mocking works in one direction (test -> code)
- How to “record” actions that happened in other processes
- How to “accelerate” time
- How to get coverage reports from code ran in other processes
Primer on multiprocessing
Let’s say that it has been a while since multiprocessing. Read on, this section will touch relevant aspects, at least for our discussion.
Empirically one can think that a process is a program per-se. Like opening a new executable from OS or opening a new tab in browser. Usually a crash in some media player will not trash the browser. This is the mindset here. And as a web page can’t easily control your media player, same is in multiprocessing. Communication and state sharing is not straight forward. Google about semaphores, events, pipes, queues, locks, they can be found in any multiprocessing tutorial.
Here I want to focus on state. How to share and communicate state between various processes? Why? Because we will exploit this massive feature of Python to “record” the actions our code makes inside a process and assess its behavior, outside, in a test.
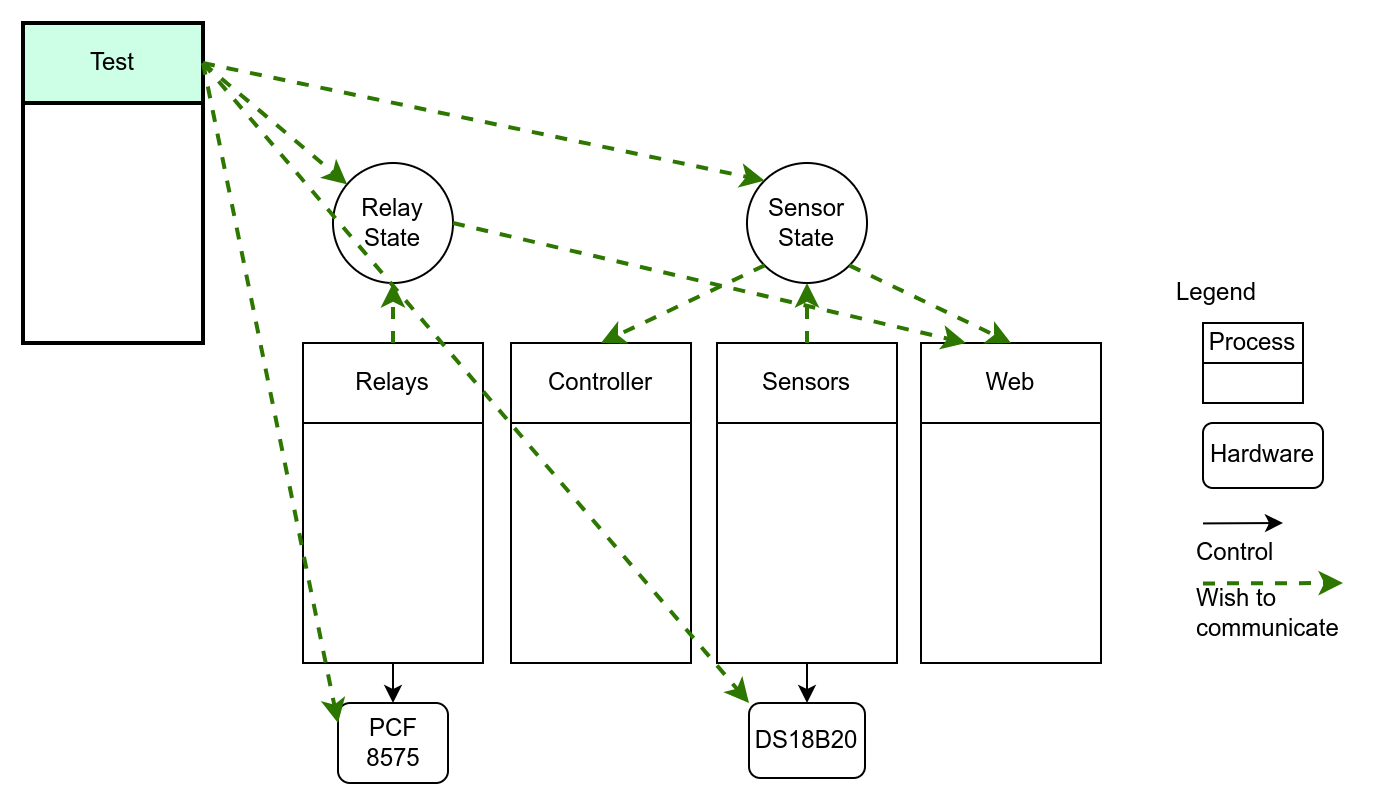
Above, is a figure showing how we wish the states and the processes to interact. Just call some methods around, like any stateful object, everything in one process. Note the Test process, that wishes to communicate with everybody! With states, with hardware layer, and probably with some internals of the processes, too!
In the figure is not shown the regular inter process communications (queues, etc). And the hardware layer objects are usually instantiated by their respective processes. They also need to have state (busses, communication state machines, etc)
The painful way of solving this problem is to have a process solely responsible to state management, process that will expose some queues. Other processes (doing business) will issue set/get-state commands to this “master” process. Sounds cumbersome? It is! Queue bureaucracy and naming will be very fun! And good luck refactoring the communication patterns!
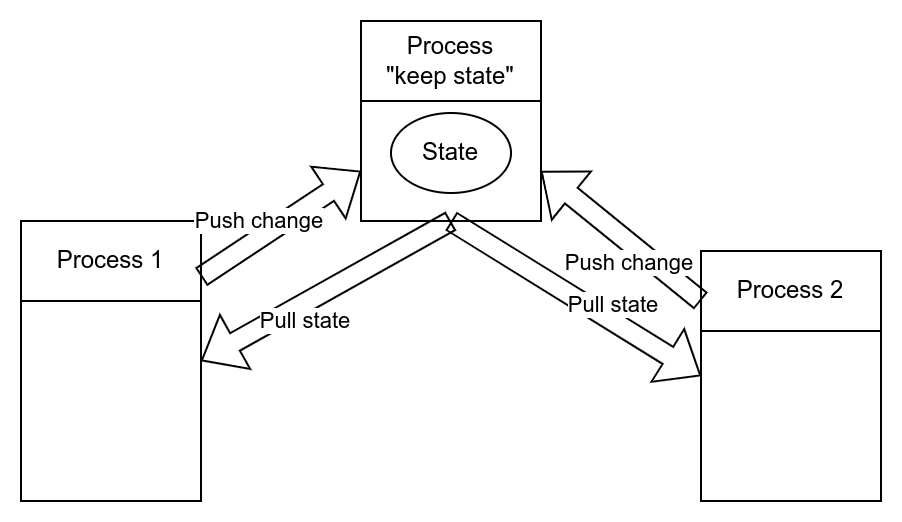
Welcome SyncManager!
Python developers already thought of this problem! This server takes care of keeping track of our unique object; it generates a proxy object that can be passed around freely, without losing its identity (and link with the “parent” Manager); this proxy knows how to pickle/unpickle the parameters and call corresponding methods in our object. The methods are proxied automatically, based on the class signature.
Cherry on top? It works over different machines! With some mild security. So Python, out of the box, offers a decent communication middleware! Not bad AT ALL in my books!
For these considerations I think it is worth paying the effort of learning how to exploit SyncManager.
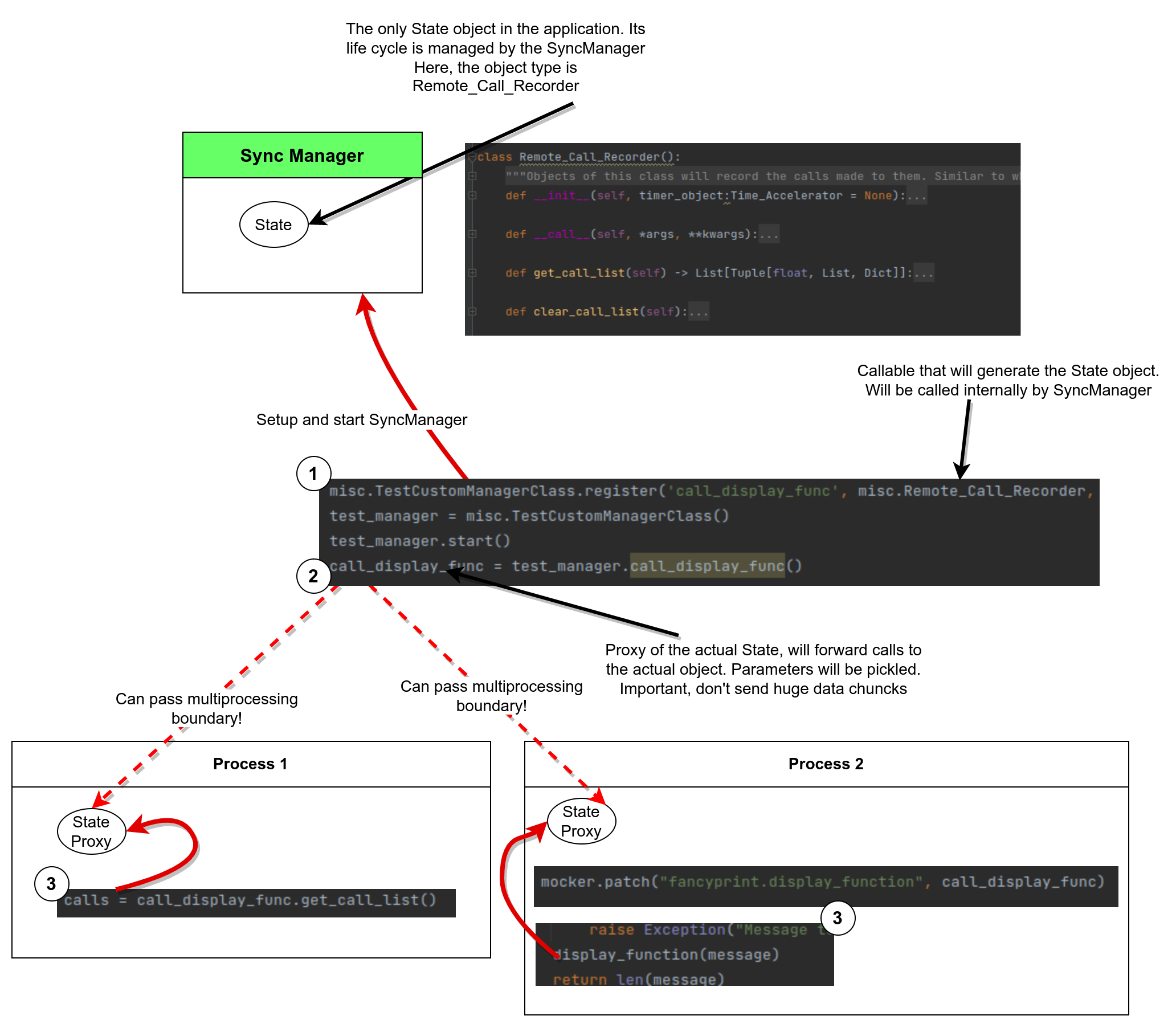
The above diagram shows some code snippets and how they interact.
First (1) we tell our CustomManger (derived from SyncManager) class to register a name and a callable for that name. The callable will be called internally by start() to generate the state object. Can be a lambda function, a constructor call, function object, etc. Flexible!
Once the manager is started, it will spawn a new process and start to listen to new requests.
To interact with our newly created state we need a proxy object. This conveniently is generated by our manager, using the name we registered. At step (2) we get such a proxy object. Now, this object is “magic”. We can pass it around through multiprocessing borders (eg call parameter or through queues) and it will maintain the “link” with the manager process.
This proxy exposes identical methods as our state object. [Can be customized]. Calling one of these methods (3) will serialize its parameters, forward a message to SyncManager process, deserialize them, call the actual method on state object, serialize the response, send it to the calling process and deserialize here the reply. For the calling code, all these are transparent!
In my Home Automation I use this pattern a lot, to store all kinds of states!
Here is a test demonstrating how to create a state object and use it around.
Let’s talk business!
Ok, you are sold to multiprocessing and its marvels! Let’s roll back to our demo.
More precise, our thin, for-show, business logic. Can we find something simpler than a Print? Well, a print but with some conditions. If the text is too long, fail with an exception.
Some constants were hardwritten! Intentionally! Not a good practice. In real life some constants might be buried deep in some hard-to-mock system wide config files, or bluntly hardcoded as here. We assume that we don’t have direct control, as we should, in the case of a good engineering!
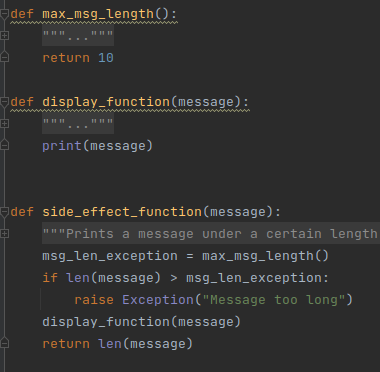
Full code is in fancyprint.py file.
Logging!
PyTest already has a fixture in place for capturing the loggers! It works, but not over processes. This test proves it. To get logs from different processes we need to follow a recipe from documentation.
In conftest.py, please note the memlogger fixture. Below, you can see a snippet.
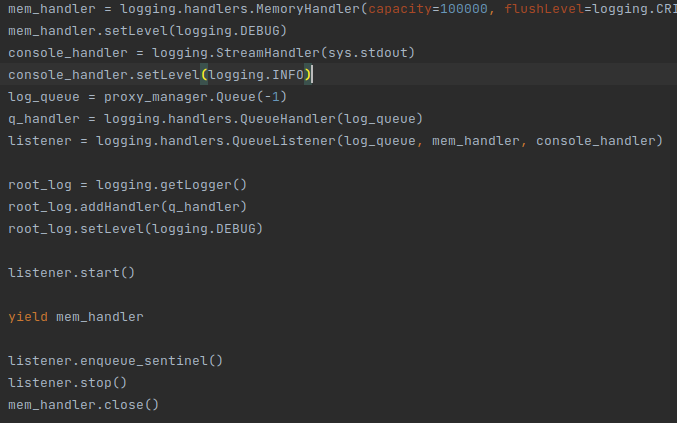
What is happening? If the official documentation is not clear, let me have a go. First, we create a storage. MemoryHandler is perfect for storing a lot of log messages. Ok, Captain obvious! Then, we create a listener (QueueListener) that takes a queue and whatever it receives thorough that queue, will forward to our storage. This listener has its own life (active object) so we can start it and forget it. The second piece of the puzzle is QueueHandler. This one will take any message it receives for handling and forwards it through the queue. Because the queue is opened using a SyncManager will be able to cross any process boundary without losing “cohesion”.
Last piece of the puzzle is adding the queue handler to our root logger. So, if a process requests a logger, this logger will have our QueueHandler present. It does not matter that is a copy of our original handler object, the queue will correctly “cross” the process boundary.
Simple? Well, it took me a while to trim the documentation sample to something bare and functional.
Cherry on top: With the magic of pytest fixtures, we don’t have to worry about contexts and wasting resources. The queues and handlers will be stopped/destroyed at the end of each test. In the demo repository there is an entire section dedicated to logging and how to observe errors in logs created by other processes.
Mocking. One way street?
Have a pesky and expensive DB connection? But your test is not focused on schemas and transactions? Rather it should ignore the DB code? Mocks are here to help! Mock the connection and the code using it will behave.
Is there a complex to setup data source? Mocks come to rescue! With their side effects, one can specify what values a function will return, exceptions, simple logic, etc. All the above work with multiprocessing, out of the box!
Excellent! But there is more! We can mock a function and check if it was called. And with what parameters. Very useful if such a function is a hardware layer. And one wants to know what and where was activated. Recording works, getting those records out, through the process boundary is not that easy.
Retrieve calling info!
But no worries, with the magic of SyncManagers we can retrieve those calls, too!
First I created objects that can record all the calls applied on them. Not method calls, but calls, directly. Similar to what a mock does. To use this class:
(1) Register it with the SyncManager
(2) Obtain a proxy
(3) mock the various calls inside the code under test, with the proxy
We launch the process, do whatever we have to do (most of the times just wait) then close the process.
We use the proxy to get the call list (.get_call_list) and assert various things there.
These tests demonstrate how to get through the process barrier, the observed method calls.
Speed testing?
Have a lengthy test with long wait times? For example, a hysteresis mechanism that has to wait x seconds for a signal to be 1, before triggering a condition. And if x, by some reasons can’t be changed during testing, what can we do?
Well, glad you asked! Speed up time!
I’ve met such situation when there were several control loops interacting, each one with different timings. It was quite hard to keep track of all the constants. It was easier to apply such a time accelerator method. I also gained a lot of abstractization! The test code is immune to tight constant timings, assertions could refer to actual production conditions and future changes in the timing schema were tested “automatically” by existing tests! Beautiful!
Oh, and my end-to-end system tests, are ran in the same manner.
This is a bonus somehow. Most of the text fixtures in this repo are used by me. And this is a piece of a puzzle that is not needed for this demonstration but fits nicely with keeping track of when a certain function was called. There is a Time_Accelerator class, that basically takes time.time() and multiply it by a value and Time_Dependent_Iterator which, upon calling, will output a value depending on what time it is! What time you asked? Well, the accelerated one, obviously! Oh, and the Remote_Call_Recorder can also record the accelerated time! Beautiful! A 24h process can be simulated in few seconds! Here, only a ~ 50 second process is simulated. The code under test switches an output after 10 second hysteresis delay.
This is my solution to Hardware In The Loop methodology. What’s wrong with that methodology? Well, it is beautiful, if you have the coinage for all the test gear! And because the grapes are sour, HiL can’t readily simulate faster than real life.
Multiprocessing coverage?
I got you covered! From IDE, yes!
I use a PyCharm A LOT! Why? Because Professional Edition! Why? Because Faculty! If you are a student, go get it! NOW! You will never look back!
In pro, with few clicks we can run all tests with nice coverage reports!

Note how fancyprint.py has 100% coverage! Very nice! But controller.py?
Controller.py has no code covered. Despite all the tests being run, the multiprocessing code was not considered.
But wait, are those coverages work in multiprocessing? Nope! Se figures above!
No worries, here is how! And we will get the nice GUI reports!

A bit of fiddling around, I admit. But then, isn’t it bad for all the hard work in spawning processes and injecting “faster than realtime” data to go to waste?
Why?
Well, the branch where there is a transition from state 1 to state 0 is not tested! Good luck in production! Muahahahahaha!