
2006-present
The bulk of my academic and industry activity is focused on computer vision. Below are some questions that I am addressing. Of course, different data, different contexts.
What this image represents?
What this image represents? Is it a hot-dog? Or a dog?
If you have this kind of questions, you will want to learn more about Image Classification. Deep learning models excel at image classification tasks, automatically labeling images into predefined categories. This finds applications in early stages of complex data pipelines. While being one of the first tasks where deep learning outperformed classical computer vision, the expectations are high, they need to run close to 99.9%.

Image classification will label each image with exactly one tag. Dog, or Hotdog! What if we have a cat in the input?
You can play, too! Fire up your favorite toolbox and start learning:
- https://www.kaggle.com/datasets/thedatasith/hotdog-nothotdog
- https://www.kaggle.com/datasets/shaunthesheep/microsoft-catsvsdogs-dataset
Have a real dataset? Let’s talk! Don’t worry about the labels, we will sort them out, somehow!
I like this shirt! Do you have a slightly different pattern?
Visual representations in computer vision solve a myriad of use cases across diverse domains, fundamentally transforming how we interact with and interpret data. Thus, visual representations serve as invaluable tools for data interpretation, actionable insights, and ultimately, solving complex real-world problems.
One of the simplest problems visual representations can solve, is searching visually similar images.
Below is such an example: We need to replace this green dress. Searching online stores is tiring. What if, we can get one glance at all other products that looks like it?

Few matrix multiplications later, we have an answer!



Of course, this is a synthetic example taken from Clothing dataset. To learn how to get visual representations for your data, the nice people at lightly.ai put up a nice tutorial.
Ping me anytime for help!
What can I find in this image? Where?
You will want to learn more about Object Detection. Deep learning enables accurate real-time object detection, with applications spanning from surveillance and security (intruder identification) to self-driving cars (recognizing pedestrians, other vehicles, and obstacles). Depending on how many details you want to know about the object, the ML can answer with:
- Bounding boxes
- Contours of the regions (eg people, sky, trees)
- Contours of each individual sample (each person, each tree, each balloon in a photo)
- Joints for persons (keypoints)
- All of the above!
Check the images below for a sample.
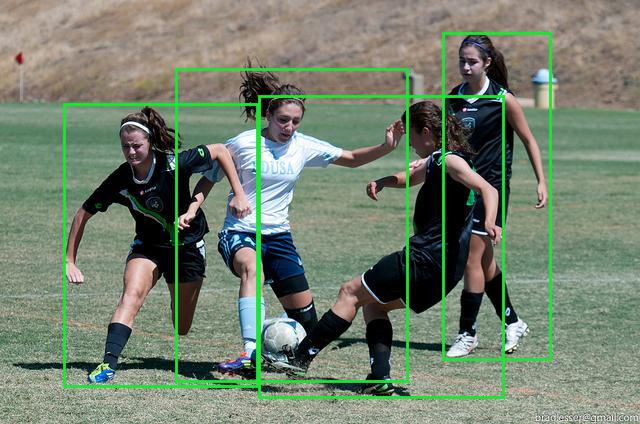


A small dataset and a good learning ground is Matteport’s Balloons dataset.
Faces, faces everywhere!
There is one special kind of “object” that got a lot of attention. That is, the human face!
Of course, the clip above is a joke! Made by Boris Babenko, it anecdotally shows where face detection should be! Unfortunately the reality still has to catch up!
Some applications require matching the face in the image with an actual person stored in some database. Face recognition is the name of the task.
Just read the instructions!
Some black pigments hot pressed on a sheet of paper have special meaning? Thin ink curves? For some (depending on the language) these strokes have meaning!
Text recognition is the name of the task, and it can come in many flavors. Recognizing text on a sheet of paper (Optical Character Recognition) or recognizing text in nature. See an example with mustard!

NEW YORK
Is that all?
No. There are more applications, but the above use cases are mostly met in real life applications. Some other areas are:
- Scene Understanding: Inferring higher-level information about a scene, such as the context, objects, and relationships present. Information is issued as keywords or as short, descriptive phrases.
- Image-to-Image Translation: Transforming images from one domain to another, like turning satellite images into maps or black-and-white photos into color.
- Image Super-Resolution: Enhancing the resolution and quality of images, beneficial in medical imaging, surveillance, and enhancing low-quality content.
- Depth Estimation: Predicting the depth information of objects within an image, important for applications like 3D reconstruction, virtual reality, and autonomous navigation.
- Action Recognition from video sequences: Identifying actions or activities performed by objects or humans in videos, commonly used in surveillance and human-computer interaction.
- Style Transfer: Transforming the style of an image while retaining its content, leading to artistic applications in image and video editing.
- Image Generation: Generative models like GANs can create realistic images, finding use in art generation, content creation, and even realistic video game environments.
Depending on the season, some might get the social media spotlight for a while.
It is all fun and games?
No. By far, NO! As with any technology, computer vision comes with security risks and limitations. Some are inherent, some are flaws that are exploited by malicious parties. Some examples:
- Samples out of domain. A computer vision system can’t predict objects/situations that were never “seen” before in the training phase. Showing a cat to a (hot)dog detector will utter one of the above two labels, without hinting the user that this might be something new for it.
- Domain drift. Imagine that the fashion changes with time. Patterns are getting “out of fashion” so our recommendation systems will silently under-perform. Continuous monitoring with some outside metric, is a must!
- Data Bias: If the data used for training is not representative of the real world, the model can inherit and perpetuate biases. This can lead to unjust or incorrect outcomes.
- Black-Box Models: Many advanced algorithms, like neural networks, offer little interpretability. This is a significant drawback for applications where understanding the rationale behind decisions is crucial.
- Adversarial Attacks: Small, often imperceptible changes to an image can fool a computer vision model into making incorrect classifications or detections.
- Real-world Complexity: Natural scenes often contain many overlapping objects, complex textures, and other challenges that are not present in simplified training data.
- Context Ignorance: Models often lack a broader understanding of the scene context, leading them to make implausible mistakes that a human observer would not.
- Costs: Labeling, Compute, Storage, all are big resource sinks. Pretrained models and public datasets can help only so much.
- Privacy and ethical concerns: Particularly in surveillance or public applications, there is often concern about the privacy implications of computer vision technologies. Using our imperfect, black-box CV methods for law enforcement or decision making raises serious ethical questions. Humans should always be in the decision loop! To censor the automated output and assume responsibility for the decisions.