

tl;dr
Brittle libraries. Hard to make them work together and the “out of the box” results are not spectacular. However, there are some tweaks that I suspect will bring up the performance.
Code, available on my github. Comments? Suggestions? Let’s connect on Twitter!
Why do I need this?
I have some datasets from Earth Observation and medical imaging (of course, from different projects). What is the common denominator? Large areas that need segmentation combined with absolute lack of labels. Labeling is very expensive. I want to solve segmentation fast, without much architecture fiddling or manually coding complex pretext tasks.
I did some literature review last year [early 2021, for a grant that was rejected] and Detectron 2 + VISSL looked like a winning combination.
This summer (2022) I had some time on my hand and decided to give it a try. I have an old GTX980Ti so I also have a hard limitation on how many layers I can cram in my model!
Both libraries are from Facebook (now Meta), both rely on Pytorch, so they should work together, right? Riiight?
Also, Mask R-CNN has been around for a while, so I expect good support in terms of documentation and little friction. In the past I had some success with U-net style architecture. But tech evolves so we must keep up!
I have to disclose that I am a big fan of fast.ai! Hands down, this is the framework where I spent most of the time. Including Weka and scikit-learn. So these dedicated, tailored frameworks were new for me.
I think there are clear advantages to these dedicated frameworks/libraries like VISSL and Detectron. A lot of details are taken care of. Training scripts and pesky configurations for learning rates, augmentations, losses, they are all set! No need to code tensor acrobatics to test one method vs another. Everything is [hopefully] following best practices! At least this is what I believed.
So, let’s go! VISSL+Detectron2, lowest hanging fruits! I did not start directly with my dataset but instead I used balloons. ~80 pictures, with segmented balloons. Also, there is a tutorial in Detectron 2 on how to do fine tuning! Perfect for me! Low data volume and custom dataset.
Installation
This is where the pain starts. Right off the bat!
VISSL install is brittle
Old Python, old PyTorch. Recommend going for the Installing VISSL from source. I managed to hack latest PyTorch version and probably I would have gotten away with Python 3.10. The “precompiled” Apex is fitted only for PyTorch 1.8.1 so one has to manually install it.
Nothing wrong with older PyTorch but torchvision was upgraded consistently and 0.13.1 is very different from 0.9.1. At least in the pretrained models.
Also, tensorboard, after trying to make it work for 2-3 times, I abandoned it. Fiddling with the conda envs takes A LOT of time! Downloading, unpacking, installing, trying the env, is a sanwich of concentration and dead time. Maybe a more polished install, next time™.
Detectron 2 is easy
Just install from source. Download the repo and go with the flow.
After hacking both, in their own envs, I managed to install them in the same environment. With errors, but whatever. My demo works. On 8 GPUs? I will test it when I will have them under my table 😉
The journey
First steps
Off the bat VISSL has broken tutorials, needed a lot of fiddling with local paths and config scripts. I had to tweak a bit the command line. I had to read a lot of source code until figured out how to change the number of epochs or the dataset or other elementary options.
One has to go very carefully over the documentation on how to work with custom datasets. Nothing very spectacular but screw a path, forget to point to the root (or to the balloon/train, depends), forget some cache and the screen will be filled with errors.
Both libraries have custom ResNet implementations, they don’t rely on torchvision. So how can I be sure that the ResNet in Detectron 2 is the same as in VISSL? In VISSL the ResNet is already called ResXNet because of some enhancements. Are they disabled by default? Requesting a ResNet50 will have these changes? Or not? That was my 1st “guess” on why the performance after SSL was low. So in this version, I started from a torchvision model.
VISSL tutorial page is now broken: https://vissl.ai/tutorials/ Try clicking around some links! So the only option is to read the code and figure out which is which. Tensorboard does not work, the VISSL “getting started” demo is a bit broken with that respect.
To pour more confusion into the mix, both VISSL and Detectron2 use some hierarchical config yamls. Of course, the recipe for one is not good for the other one. Same with various parameter tweaking.
Can Detectron 2 work with torchvision? Oh glad you asked! The coding model is radically different. Each “layer” must output some dict of name->actual layer. The names are different from the torchvision implementation. Luckily they provide a conversion script. But am I certain their ResNet follows to the letter the torcvhvision one? In the conversion script is mentioned a slightly worse performance when using a torchvision backbone compared to their fully pretrained models. Slightly you say? Well, finetune on a model from Detectron 2 Model Zoo, AP = 80. Load on the same zoo model, then overwrite the backbone with the torchvision weights, then do the same finetuning, AP=50. Hmm . . . .

The two major architectures used here. Both have a backbone and a head. Each library has its own model zoo and its own architecture (network definitions). They are not directly compatible.
After some fiddling, they both accept a ResNet from torchvision, and they both can do some training. How about evaluation? In VISSL I have no idea how it is done [it is not obvious and I did not search]. In Detectron? With custom dataset? Well, the eval code silently creates some files on disk, files that are then injected in the dataset “metadata”. Want to re-do the evaluation? And somehow that file was lost? Prepare yourself for few hours of questioning one’s life choices . . .
On a positive note, the Detectron 2 library can handle almost out of the box multiple planes of color. If the dataloader retuned 4 channel images, it adapted the 1st layer automatically. Nice! Useful for Earth Observation.
It finally works! But does it now?
The bytes are finally flowing! I can take a ResNet50, train it through VSSL with some pretext, take the backbone from VISSL and export it to Detecron 2. It is time for some experiments!
E1. Sanity check
Are the bytes flowing correctly? Am I doing something wrong that will blow out the performance? A good test is to let the bytes flow but barely train the backbone.
I started from Detectron 2 ResNet_50 pretrained Mask-RCNN. Finetuned it on balloons, with only 20 images (some 50 epochs or so). Segmentation AP on test set, ~80. Ok, not bad! I have a baseline!
On top of the above pretrained model [without finetuning] I took the torchvision weights and load them. Then, the same fine-tuning as above. Results? Meh. AP=50. Why? Don’t know. But at least I know there are some issues with these weights. So AP=50 is the new baseline. Pro Tip: When your method is weak, find a weaker baseline! </sarcasm>
Now we bring VISSL into play. I took the same torchvision ResNet50 and load it up, on top of SimCLR-ResNet50 pretrained task. This task is demonstrated in VISSL tutorial. I did few epochs, with few images. Enough to change the model but not significantly. Exported to Detectron 2, and then finetuned with exact the same setup as above. AP ~45. Ok!
The bytes are flowing, there are no bad things happening loading/saving the weights in VISSL. The performance after the model went through VISSL is roughly the same.
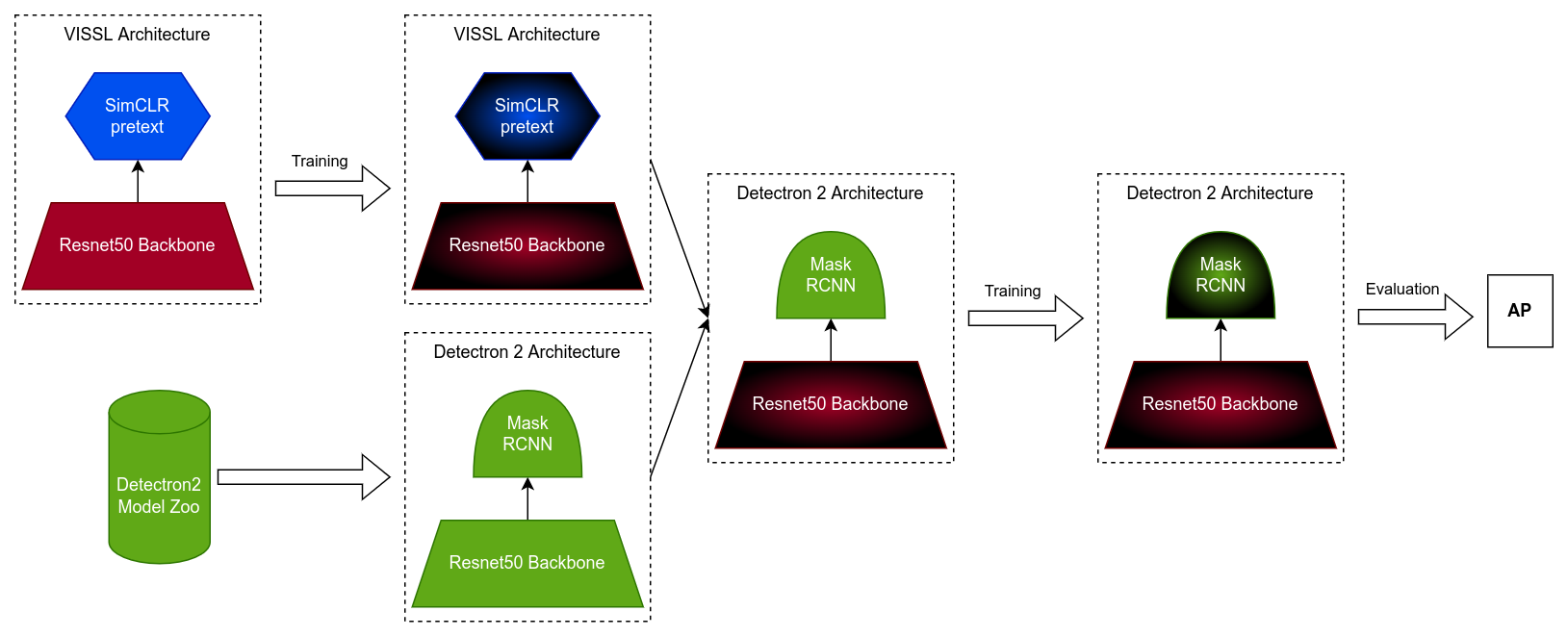
The train pipeline. I start from a pretrained VISSL model with torchvision, backbone. Train the SSL architecture and export the backbone to a Detectron 2. Train and evaluate the Detectron 2.
E2. Learning
Same as above, I started from a torcvhvision model, this time the VISSL training loop was unleashed! Full train set of 61 images, for 500 epochs! It takes a while, the learning rates are going all over the place (up to 3). Is it normal? Had to maybe tweak the scheduler a bit. I don’t know, I did not investigate (neither read the paper that explains the scheduler). Some configurations listed different policies depending on the dataset/number of epochs. Damm fast.ai with their one_cycle() policy that handles everything for you! Now I can’t even read a scheduler properly!
Anyway, the loss [train? test? which percent?] is also going up and down. But who knows? Maybe this is the way. Is the best model saved in the end? Or am I using the latest? Hmm . . . . I blame fast.ai again for making rationale choices for us! Here, I take the last exported model by VISSL, regardless of its performance.
Good, good, now let’s go for the kill! I took the weights, loaded them in Detectron 2 and fired up the same finetuning. Results? AP ~1.8. One point eight. On a scale from 0 to 100.
Press F to pay respects.
Conclusion
Dino? Transformers? Well, with a 980Ti is hard to approach anything bigger than a ResNet50. I didn’t even consider Dino. But maybe, the setup, maybe a lite transformer, who knows?
Fast.ai. There, one has to get their hands dirty, create a model from backbone/head and then search or code the pretext tasks. Segmentation is supported with respect to to data augmentation. Mask-RCNN? FPN? I don’t know. At least U-net is supported directly.
Why the performance is low?
My guesses are:
High confidence
SimCLR pretext task is NOT fitted for segmentation. I identified several other pretexts (from VISSL) like PIRL, Colorization or SwAV.
SimCLR might be ok, demo data augmentation might be unfitted. Segmentation must focus on a range of scales. Reading the quick_1gpu_resnet50_simclr [without any code digging] a crop of 224 x 224 might not be suited for detecting balloons. They are usually larger.
Not enough learning time. I ran the SSL for 500 epochs on 61 images. Looking at the Colorization setup, they ran ImageNet-22K for 28 epochs on 8 GPUs. Counting how many images are in ImageNet (14M+) and how many are in balloons (61), well, it is clear that my model had waaaay too few gradient evaluations. On the other hand, Detectron 2, with ~50 epochs, on the same dataset, reaches decent performances! However, selling point of SSL is not faster training but removing the need for labels.
Medium confidence:
Some screw-ups from my part, at the learning rates (the LR scheduler creates learning rates up to 3).
Low confidence:
Wrong plane colors/statistics when loading model in Detectron 2. By default, the R-CNN model in Detectron 2 uses BGR ordering. The ResNet in torchvision uses RGB. VISSL does not specify any plane conversion when loading torchvision models so I assume that is the same as in torchvision. However, the slightly VISSL-touched model behaved roughly the same as original torchvision model. If the VISSL import/export did something bad with it, its performance would have been far worse. However, there is a chance that VISSL pipelines (augmentation code) encode the data in other format. But this is not mentioned in the “how to use torchvision” section of the VISSL docs.
Now what?
When I will have another slice of time, I want to take another swing at this. Maybe spend some time with VISSL, maybe switch to another segmentation architecture…I am somehow reluctant to pick a less popular git repo, just because there are promises of performance.
In the meantime, if you have any comments, suggestions, saw some obvious bugs, please feel free to connect with me on Twitter (see the blue button below).
Cheers!