

Tl;dr:
I want to do fine tuning (or transfer learning) for instance segmentation (MaskRCNN) but not directly but with the help of self supervised learning. The supervised dataset is very small (16 samples) but the SSL train set is a bit larger (~60 samples). [1st attempt/iteration is here]
Findings:
For segmentation tasks, I still couldn’t find a way for SSL to yield results, if the dataset is small. For classification (and probably retrieval) SSL is ok even with ~1K range samples.
Takeaway: If a client approaches me with a segmentation task, time will be better spent labeling new data than fiddling with SSL pipelines.
Meta-takeaway: If a clear, plausible tutorial, with similar dataset (same modality, similar task and data volume) is not available, the problem might require more than 200 hrs of work.
Upside: Community was nice, helpful. Almost discovered a bug (wasn’t a bug)
List of resources:
Datasets

The Freiburg Groceries Dataset.
It is a classification dataset, 5K images, 256×256 images, ~0.5GB. Images are tightly cropped. There is a test set with larger images. One must create their own train/test split.

(better) CIFAR data on kaggle
Small images, 32×32, individual images (easier to view/prototype with them than with official release)

Matterport Inc, balloon dataset
This dataset is from their awesome tutorial on segmentation! The tutorial is in tensorflow but the data is agnostic.
In this dataset there are train/val folders, the boxes and masks are in json but the authors show how to extract it and converting it to how torcvhision model wants it, was fairly easy.
Code
Collab on how to train MaskRCNN using torcvhision on custom dataset. I used it to adapt the dataloader for balloons.
Adapt balloons to Detectron2 and fine tune a MaskRCNN. Again, very helpful in figuring out the dataloaders. And of course, how to fine tune a model using Detectron2.
Lightly.ai is a company that open sourced some of their components. It triggered the current iteration because they offer SSL building blocks without constraining you to a framework (cough ViSSL)
Torchvision MaskRCNN using lightning framework. Useful to get a second look at the implementation. I used the torchvision MaskRCNN tutorial to adapt a lightning module on top. However, there are issues with the validation/evaluation part that I couldn’t solve in the allocated time.
Promises, promises
Self Supervised Learning promises to trade the need of labels for compute power! For all downstream tasks. This was proven over and over again in various papers, from large groups.
But science is a culture of doubt! Does it work for my dataset? Can I do transfer learning, like one can do with “regular” models?
My use case
I have a small dataset (~60 images or so) some of them (16) are segmented. I also have some validation data (13 images).
I want to do a fine tuning (or transfer learning) of some network, so those 16 samples will yield very good segmentation performance without the need to label more images.
Dataset? Balloon! (37 MB) There are 61 train images that will go into the SSL pipeline and only 16 of these to the supervised segmentation. The dataset contains labels for all 61 images. Training a supervised model on them is very much possible and it is probably an upper bar for the expected performance. A baseline (that must be crossed) is supervised fine tuning on only 16 images.

After some fiddling with two famous libraries ViSSL and Detectron2 I decided to take another approach, with more coding and less guessing of what’s underneath. The “breakthrough”? Lucas, from Yannic Kilcher’s channel, told us about lightly.ai!
Nice and clean code-base, an example for Detectron2, wow! Must try it! I shuffled my schedule and priorities to throw some hours at the problem, again! I mean, shouldn’t take me THAT long, right?
Conclusion
Don’t scroll to the bottom, here are the spoilers!
Conclusions after current iterations:
Transfer learning through SSL works really well for classification tasks! This was a proxy for me, to validate the pipeline (dataloaders, augmentations, etc).
For segmentation, at least MaskRCNN, the SSL setup that I tried is not good. Roughly the same performance when starting from a torcvision vanilla ResNet versus a heavily SSL tuned ResNet. And finetuning the fully pretrained network is way better, even if it is done only with those 16 images:
| Starting model, with weights | AP@[IoU=0.50:0.95] |
|---|---|
| MaskRCNN with pretrained weights | 0.825 |
| MaskRCNN with pretrained FPN weights and torcvhvision ResNet weights. | 0.534 |
| MaskRCNN with pretrained FPN weights and torcvhvision ResNet weights that were through 5000 SSL iterations | 0.491 |
Overall conclusion: For few images it pays off to label more data than fiddle with coding a SSL loop. There are no “ready made” tutorials for custom, small datasets. The effort put in coding the pipeline is better spent in labeling. Already sunk 150+ hrs into this iteration.
Assumptions from previous iteration
SimCLR pretext task is NOT fitted for segmentation or data augmentation is bad. Yes and No. Data augmentation is not good but there are papers trying to circumvent this (by guided cropping) or ignoring it and just pumping the volumes up (majority of SSL papers where segmentation is just another downstream task)
Not enough learning time. Yes! Going wider (in batch size) and throwing in significantly more compute yielded nice SSL learning curves and useful backbones!
Optimizers and schedulers. Tweaking them helped with learning but not decisively.
Wrong plane colors/statistics Ruled out early (or, at least, fixed early in this iteration)
The story
Oh, still here? Ok, I will share what I did and where I got inspiration from. Maybe it will be helpful for you.
Rewinding, the trigger for current iteration was Lightly framework. Off the bat, the juicy Detectron2 + SSL tutorial was properly broken. No worries, I know how to start a Detectron2 training loop from the code!
Also, the overall library API looked nice and neat! Like fast.ai library! So I decided to invest more time with Lightly library.
Initial tests were done on a classification task. That is, on top of the SSL trained backbone I attached a linear layer that was trained on a classification task. The performance of the classification task showed if the SSL did something good or not.
Step by step, confirmed that the Balloons set was loaded and augmented properly by SSL loop, added a color plane shift in the transformations, but there was no SSL learning. The loss lines decided to remain flat.
Switched to tutorial 2 but on CIFAR data. Smaller, maybe they will fit in my 6GB GPU! And they did! Some tiny learning was happening! Switched from MoCO to SimCLR and the classification accuracy raised from 0.34 to 0.38 with the validation accuracy of the SSL backbone consistently above the vanilla one! So, first win. SSL works for classification.
However, larger batch size or larger images were bust. OOM. But, encouraged by the results, I switched to a beefier GPU. 32G! Downside? Not always available and maybe some costs down the line.
Machines are learning (to classify)
Welcome to The Freiburg Groceries Dataset! 10% used for supervised classification and 100% for SSL! Out of train0.txt. The test0.txt went into the validation set for the classification task.
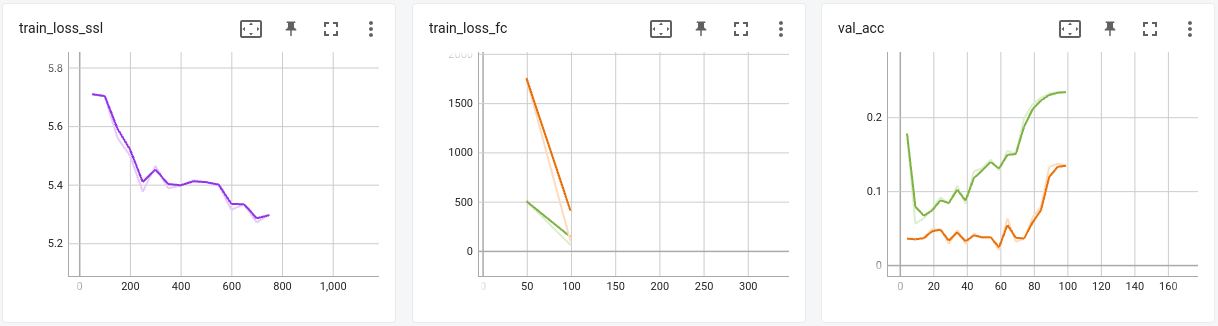
Left: SSL loss, while trainig, Center: Loss for fully connected layer, Right: Validation accuracy after each training epoch for the fc layer.
Orange: fc layer on top of a randomly initialized backbone. Green: fc on top of the SSL trained backbone.
First non trivial result for this iteration! SSL is making the difference! Batch size 256, ~50 epochs for SSL. Far Cry from the compute that I put in initial experiments. More tweaking, larger ResNet (now ResNet 50, before it was ResNet 18), checkpointing, more epochs, and I discovered that the end classification accuracy grows monotonically with the drop in SSL training loss! Awesome!
Detectron2 here we go fail again!
Good, good, classification works! My goal is segmentation! Time to bring the weights from a segmentation model, not a generic ResNet.
I took 3 sources: Vanilla torchvision ResNet, the backbone of torchvision MaskRCNN (still ResNet architecture but different weights) and of course, Detectron2 (mask_rcnn_R_50_FPN_3x.yaml config). Each donor network “donated” the entire backbone, that is weights+architecture. So we don’t run in importing issues or 3×3 vs 7×7 mismatches.
First WTF moment! Whatever I did, the Detectron2 backbone yielded poor results. Tweaked the plane colors, the image statistics, nothing. Even weirder:
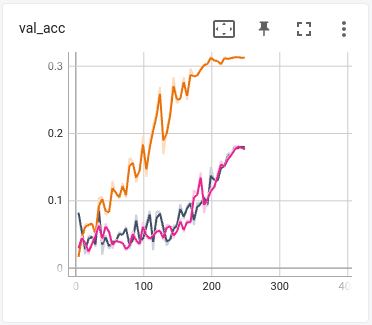
fc accuracy when doing SSL from different types of Detectron2 weights.
Starting from a randomly initialized Detectron2 ResNet, yielded the orange curve. Loading the D2 weights, black and magenta. Black is with RGB ordering, Magenta with BGR ordering. Like it does not care. Lost a few good days in a wild goose chase. Plotting statistics, weights, activations, wildly changing statistics, no definitive answer on why, the D2 architecture is that rigid to SSL learning. The main suspect? The Frozen Batch Norm layers. Out of scope so I abandoned D2 direction.
Fallback to torchvision
Detectron2 is not the only library doing segmentation. Vanilla pytorch has a model! And a tutorial! I switched to balloons and carefully validated the data loaders.
Few days later, after checking every step, I can do “vanilla” finetuning on balloons, with 16 train images!

Torchvision MaskRCNN detects balloons on a test image. Note the makeshift visualization.
Ok, no SSL yet. And Detectron2 was also able to finetune on balloons! Oh in the meantime, added lightning.ai into the mix! Highlight of the “day” was that Adrian Wälchli created an issue in lightning github after me complaining on Twitter! Big plus for the Lightning-AI people! The next day I reproduced it into a collab. Turned out that it wasn’t a bug. I was too tired and missed a big warning on the output.
Also got some tips from Lightly.ai people so overall this particular corner of ML was superior to, well, other corners 🙂
Few more days with tweaks and code validations followed. I switched to a generator dataset so I can have an infinite number of iterations for SSL. With 60 images in the training set it was hard to bump the batch size. Turns out that larger batch size brought more benefits than the downside of having same image both on positive and on negative set (because same image is taken several times in a batch)
I couldn’t make the lightning module perform a proper validation during training. Pure torchvision implementation relies on PyCoco which expects the dataset to be available before training. Bugged me and I wasn’t in the mood to scoop out the code that does the actual IoU math. And to test that code, of course. So, one AP evaluation at the end of the segmentation loop, with an already validated torchvision implementation.
Now I was ready to perform the learnings on the segmentation task!
The tests
The setup was:
- ResNet 50
- Balloons dataset, 61 images (train set) on the SSL training set, first 16 images (two batches) for segmentation training and 13 images (val set) for performance measurement of the segmentation task.
- I started from some architecture with or without pretrained weights taken from several sources.
- I did SSL training with SimCLR with Batch Size of 128 (max-out on GPU memory)
- Created a MaskRCNN model following the torchvision tutorial. Create new box and mask heads with two classes.
- Loaded some MaskRCNN weights:
- Optionally, I loaded pretrained weights.
- Optionally load some external backbone (bottom up) weights.
- Operations are done in the above order.
| Resnet Source-> MaskRCNN Source ↓ | Default (from the MaskRCNN model) | Pretrained from torchvision | tv.ResNet -> SimCLR, 500 iterations | tv.ResNet -> SimCLR, 5000 iterations |
|---|---|---|---|---|
| Random | 0.032 | 0.014 | 0.041 | 0.029 |
| Pretrained | 0.843 | 0.465 | 0.463 | 0.418 |
Random weights yield random results. Pretrained weights yield best results! SSL looks like it does more harm than good.
I noted the difference between the best result and the rest of the results: The FPN part! It is loaded with the pretrained weights and never overwritten. Regardless on how good or bad the bottom-up ResNet is (original, standalone, SSL trained), if the FPNs are random, the results are random.
Let’s see if there is a way to get the FPNs into the SSL loop. Few google links and I stumbled upon SoCO! Whole MaskRCNN into SSL! Awesome results! SOTA! Paper well explained, code available! Cloned the repo, took the docker and failed. Ok, some keys failed to be loaded, but nonetheless, I quickly abandoned the paper. Unmaintained for 12 months, and several major libraries were forked, changed somehow (lots of commits “ahead”) and then loaded into the docker. Moving on.
Another paper, claiming they solved MaskRCNN end to end SSL, was MaskDINO. Code available soon™. Nothing to do there.
Overall, it wasn’t a good day for science.
Pump those numbers up!
In the SimCLR papers and whatnot, the downstream tasks are trained fully, same as one would do in a pure supervised fashion. What if I push more iterations in the supervised segmentation part? But keeping the data low?
I also added in the mix more tweaks, like cosine annealing, freezing/unfreezing the model in mid training, etc.
| Model with weights | AP@[IoU=0.50:0.95] |
|---|---|
| MaskRCNN with pretrained weights | 0.825 |
| MaskRCNN with pretrained FPN weights and torcvhvision ResNet weights. | 0.534 |
| MaskRCNN with pretrained FPN weights and torcvhvision ResNet weights that were through 5000 SSL iterations | 0.491 |
Tweaks helped quite a lot but the ranking stayed the same. Well, end of iteration 2.
Unexplored avenues:
- For SSL, take the weights directly from the bottom-up part of MaskRCNN (done for classification, why didn’t I do it for segmentation?)
- Hack a way to take the FPN output as part of the SSL backbone. Concatenate the Px outputs? Do some pooling? Didn’t find some answers on google.
- Maybe the SSL data and segmentation domain data are not matched? SSL pipeline takes a crop out of a large image and scales it down. Some objects might get reduced to pixels. The MaskRCNN pipeline works on “full resolution” so objects of interest are well represented.
A solution could be smart data augmentation. I mean, I do have the training labels! How about cheating and using them to guide cropping? If performance blows out, then I know where to dig! As far as I remember Yann LeCun told us that SimCLR is very sensitive to data augmentation. One of SoCO tricks was to crop salient patches. - Spend some time (segmentation) labeling the test set from Freiburg Groceries? In the test set, I have quite large images with objects from the train set. Having a train set w already cut images, and a SSL pipeline that yields (confirmed via classification) might help confirm the “unmatched domain” hypothesis?
- Try other types of SSL? Hard lesson learned from SimCLR, when nothing worked until I pumped up the batch size.
- Take a bigger step and move to transformers. How many GPUs do I need for those, just to debug the code?
Anyway, ideas are welcome! Same for a beefy 8-GPU machine!